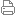
1 TB 数据存储资本 8 亿美元,照旧有点高。
恐龙灭尽 6000 多万年后,科学家们得到了一块有史前蚊子的琥珀,从蚊子血中得到了恐龙的基因,从而让迢遥的生物复活。讲这个故事的《侏罗纪公园》,至今仍位列环球影戏票房前十。这个系列故事的原理很简单:DNA 存储了恐龙的生物信息,科技让它重新表达。
现在,用 DNA 想象另一个故事:在宇宙长河中,「人类世纪」也寂灭了。别的一种智慧生物出现,TA 们去探究太古的「人类文明」。有什么会承载人类文明的影象?气温异变,地球上的巨大数据中心徒留遗迹。
而冻土中有一份 DNA,它很轻,只有 1 公斤,看起来是一些被封装在胶囊里的白色粉末。读取后,内里却纪录了地球上曾有的巨量信息。视频、笔墨、代码显现了人类汗青进程中的无数发明和文艺作品。于是谁人迢遥文明的陈迹在宇宙间再次睁开。
这是另一个科幻设定了。背后的技能正是现在被关注的一个前沿方向:DNA 存储信息。在大天然里,DNA 负责存储遗传信息。单个人体细胞的均匀直径是 5 到 200 微米,这此中的 DNA 可以包罗一个人全部的遗传信息:30 亿对碱基。
那为什么不能用碱基存储别的信息?这个科幻般的假想,正在走出实行室,被当作信息存储的将来方案。
01 基因组数据太多了,怎么办?
原来是生物学家想办理生物学发展的题目。
11 年前,一群生物信息学家在德国的一家旅馆里讨论「数据存储题目」。Nick Goldman 也在此中,那是他在欧洲生物信息所(EBI)担当高级科学家的第二年。
大规模的基因组测序正在举行,随之产生的数据规模快速增长。存储、压缩这些数据是个贫困事,现有的技能方案看起来不太行。据估计:人类基因组必要高达 2-40EB 的存储容量。这大概高出一个天下级科技公司的云存储量——全天下苹果用户存储在谷歌云上的数据总量约莫是 8 EB。这 8EB 数据,每月存储费必要 2.18 亿美元。(1EB= 102^3GB)
生物学家们陷入了沮丧。
Nick Goldman 拿着存储了莎士比亚全部十四行诗、一张照片和「我有一个空想」演讲片断的 DNA| 泉源:EBI
有人灵光乍现:是什么东西克制了我们用 DNA 来储数据呢?
看起来是一句打趣话,但是生物学家们意识到了这不但仅是个打趣,他们拿起手边的餐巾纸,用圆珠笔认真盘算起可行性。
DNA 存储遗传信息的原理并不复杂,它由四种核苷酸 A、T、G、C 构成,相互两两对应,构成双螺旋结构。核苷酸的序列,记载了遗传信息。
在数字天下,全部的信息本质上是 0 和 1 构成的数据串。想要 DNA 存储数字信息,简单明白,原就是将 0 和 1 的编码序列转换成核苷酸的序列。DNA 存储的上风在于密度大,约莫在你眼前逗号这么巨细,1 立方毫米的 DNA,就可以容纳 9TB(1TB=1024GB)的信息。
用 DNA 存储数据,也并不是完全新的想法,之前就有科学家实行过。不外属于科学和艺术的先锋跨界实行。
1988 年,艺术家 Joe Davis 和哈佛大学的研究员,将一副名为「小维纳斯」(Micro Venus)的图案存储到 DNA 短链中。
存储进 DNA 的小维纳斯(microvenus)图片 泉源:相干论文
这个图案编码浅易,白色的地方标志为 0、玄色的线条部门标志为 1,文件巨细只有 35bits,用了 28 个核苷酸长度的 DNA 链条来存储。
在那次旅馆讨论的 2 年之后,2013 年,Goldman 团队发表了研究结果。这次,他们存储了 5 种差别格式的文件,一共有 0.75MB。为了确保信息读取不堕落,科学家存储的时间,每份信息按照四倍冗余的量来存储。
五个文件分别是:
154 首莎士比亚的 14 行诗(ASCII 编码格式)
提出 DNA 双螺旋结构的论文(PDF 版)
一张照片(JPEG 格式)
马丁· 路德金「我有一个空想」演讲此中 26 秒片断(MP3 格式)
一串霍夫曼暗码
这些年,DNA 存储容量的上线不停被突破。2019 年,美国一家创业公司 Catalog 在 DNA 中存储了 16GB 的维基百科。这个公司表现本身正在建立天下上第一个基于 DNA 的大规模数字数据存储和盘算平台。
02 编码息争码,要处置处罚的事变很多
在一些生物学家看来,用 DNA 来存储是一件非常「顺滑」的事。「大天然的编码语言非常雷同于我们在盘算机范畴使用的二进制语言。在硬盘上我们使用 0 和 1 来代表数据,而 DNA 中,我们拥有 4 种情势的核苷酸,A、C、T 和 G」。在瑞士联邦理工学院的生物学家 Robert Grass 说。
DNA 存储的关键之一是用四个核苷酸去映射 0 和 1 两个数字。方案可以很简单。比如:A 对应 00,C 对应 01,G 对应 10,T 对应 11。然后再按照所必要的核苷酸序列,像串珠子一样,把核苷酸们串成一串。(这就是 DNA 合成)必要读取信息的时间,再运用基因测序技能,把这一串核苷酸序列读取出来,再翻译成 0 和 1 的字符串。这个流程就是编码—DNA 合成—测序—解码。
这个听起来像是「把大象装进冰箱」的流程,利用起来必要思量的题目尚有很多。否则科学家就不必不停研究新的编码方案了。
在天然界存在的 DNA 中,A 和 T,C 与 G 两两配对,在一条 DNA 中,CG 与 AT 的存在比例根本匀称,为 50% 左右。如果 C 和 G 的含量过高,大概会让 DNA 链产生一些复杂的物理结构。这就会让 DNA 测序(解码)变得复杂。
DNA 存储的步调| 泉源:DNA Data Storage Alliance
而且在「串珠子」(也就是合成 DNA 链条)的过程中,错误率不可制止。现在约莫每合成 100 个碱基就会出现一个错误。这是由现在的化学合成技能带来的瓶颈,每合成一个碱基,有 99.9% 以上的精确率。但是当碱基串变长,0.01% 的概率相乘,错误就难以制止。现在人工合成 DNA 的单链的长度一样平常不高出 100 个碱基,极限在 300 个碱基左右。而在天然界的 DNA 动辄有几千个碱基对。
也就是说,固然 DNA 的存储本领很强,但它们不得不以很多条短链的方式存在。如果存储的信息量比力大,这些 DNA 短链就像一本散装的书。它可以存储很多信息,存在情势却是一张张标着页码的纸。固然,可以将一条条 DNA 短链拼接发展链。这就意味着增长了一道工序。在测序的过程中,又必要把长链打断成短链。这是由于现在技能还不能一次性读取长链。
在测序的过程中,也存在错误率。只管现在的错误率已经低至 10^-3 数目级,比起贸易硬盘的读写错误率,仍相差至少 9 个数目级。
精确率受到合成和测序这两项技能的影响,科学家想到计划编码方案来制止:在编码中增长纠错机制。如许,哪怕碱基合成和测序中出现了错误,仍然可以大概包管被存储进 DNA 的内容可以大概被精确读取出来。
03 走出实行室,还要思量速率和资本
DNA 存储也正在实行走出实行室。
2020 年 10 月,微软、西部数据和基因测序巨头 Illumina、DNA 合成初创公司 Twist Bioscience 等团结创建了 DNA 数据存储同盟。
这是天下上第一个该范畴的学术和产业链同盟。这个同盟盼望订定技能和格式标准,终极创建一个可以通用的贸易体系。
微软研究院在 2015 年就创建 DNA 存储的项目,并约请了华盛顿大学的盘算机科学与工程学院的副传授 Karin Strauss 担当高级首席研究司理(Senior Principal Research Manager)。
2013 年,她和同事去英国 EBI 访问,相识到 Goldman 和同事们关于 DNA 存储的研究,就对这个方向产生了很大的爱好。Strauss 说,「DNA 的密度、稳固性和成熟度让我们高兴。」
在他们的研究中,想开发的是另一个功能:随机读取。常见的 DNA 测序技能中,必须要将全部的碱基串一次性读取完,才气够得到信息。要么不读取,要么全读。如果只想要数据中的某一个小片断,就会非常贫困。
2016 年,他们发表了一项研究,可以在 DNA 已经存储的信息中搜索到指定的图像,定位后,用酶来复制所需的 DNA 片断,然后只需读取这一小段即可。
Karin Strauss(右)和两位研究相助者|泉源:csenews
要让 DNA 存储离商用更进一步,还必要办理合成速率和资本。现在合成速率是每秒存储上千个字节(KB),成熟的云存储方案已经有每秒千兆字节(GB)以上。
这意味着,编写 DNA 的速率还必要提拔 6 个数目级。怎样让提拔数据处置处罚量?就像并行盘算可以大概提拔数据处置处罚速率,科学家盼望 DNA 在合成时也可以并行多条,同时处置处罚。
2021 年,微软开发出首个纳米级 DNA 存储器,可以大概在每个平方厘米的地域上,同时合成 25X106(2650)条碱基序列。这个新的技能把原来同时合成碱基序列的数字从个位提拔到了千位。这个吞吐量,让 DNA 合成速率酿成了每秒兆字节(MB)。
新的方法让 DNA 合成的阵列数目大大增长|泉源:微软研究院
更大的吞吐量,也就意味着更低的资本。现在 DNA 存储的资本是每万亿字节(TB)8 亿美元。而磁带存储资本已经降到了每万亿字节 16 美元以下。如许比起来似乎毫无竞争力。但实际生存中的大型数据中心的维护资本极高,还要定期更新硬件;DNA 存储密度大、体积小、可以长时间稳定质的上风就酿成了降维打击。
以是量大、读取频率低的「冷数据」,被以为是 DNA 存储近来的应用场景。Twist Bioscience 近来在一份市场陈诉中夸大,这种技能可以大概资助科技企业在「大规模、低功耗」环境下更有效地摆设。
别的一些乐观的科学家,更信托技能的进步。
自 2003 年人类基因组操持完成以来,测序资本低落了 200 万倍。2016 年时,面每秒千字节的速率,Goldman 说,「(读写的速率提拔)6 个数目级对基因组学来说没什么大不了的。你只必要再等一会儿。」
那这「一会儿」是多久呢?这个范畴似乎到了临门一脚,仍在期待突破。 |